Top 7 Anonymization Techniques to Sustain Data Privacy and Compliance Standards
|
Listen on the go!
|
In an era where data breaches generate headlines and data privacy is an increasing concern, how can organizations use the massive amounts of data they acquire without jeopardizing individual privacy? The solution could be found in a unique amalgamation of data anonymization approaches. As we dive into this fascinating topic, we discover how technology is transforming how we anonymize data, ensuring that the insights we gain are useful and respectful of privacy.
Anonymization techniques preserve data privacy and comply with regulatory requirements. Organizations can reduce the risk of unauthorized access or disclosure by deleting or masking identifiable information from databases, such as personal details or sensitive qualities. Data masking, aggregation, and encryption are techniques used to keep data anonymous while making it usable for study and analysis. These approaches not only protect individual privacy but also comply with regulatory standards, creating trust and responsibility in handling sensitive information in various areas such as healthcare, banking, and research.
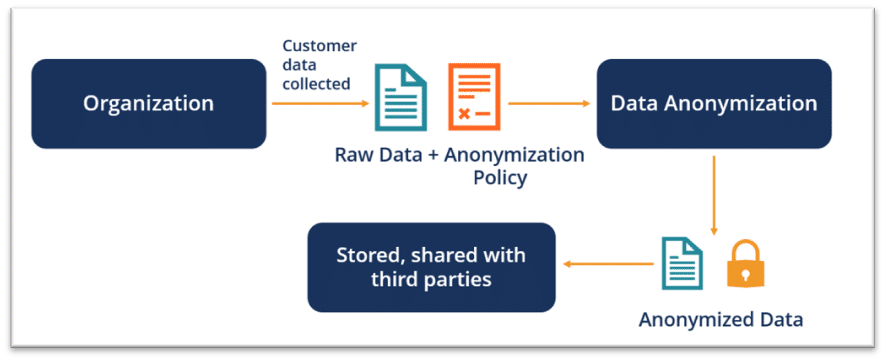
Here are some key data anonymization techniques:
- Data Masking: Obscuring most of the data while retaining the last or first few data visible (e.g., xxxx-xxx-1234), ensuring partial concealment for privacy.
- Data Generalization: Showing data in a generic way to prevent identifying the owner, like displaying age ranges instead of birthdates (e.g., 21-30 years old).
- Noise Addition: Increase data security by adding controlled noise. For example, instead of representing the patient’s original systolic pressure as 120 mmHg, use 118 mmHg (original: 120 mmHg +/- 2 mmHg)
- Permutation: Shifting or shuffling values inside a column to obscure the original relationships between data points. For example, in a dataset with sensitive information in rows 10 to 50, applying permutation would scramble these values to prevent specific individuals from being identified while retaining the dataset’s general statistical integrity. This technique protects privacy while still allowing for helpful analysis of anonymized data.
- Pseudonymization: Replace the original data with encrypted versions. For example, a healthcare database might encrypt patient names to ensure confidentiality while retaining data integrity for research and analysis purposes.
- Suppression: Eliminates sensitive data, lowering utility. In a marketing dataset including client information, sensitive details such as individual email addresses or phone numbers may be concealed before analysis. This protects client privacy while allowing researchers to study broader demographic trends.
- Synthetic data: Replicates statistics to protect privacy in analysis. For example, to evaluate fraud detection without using genuine client information, synthetic data in finance imitates actual transactions, guaranteeing security and privacy.
As we have just seen, “personal data” encompasses a wide range of information, and most businesses are presented with it. Most data protection specialists recommend establishing a data anonymization procedure to minimize difficulties and comply with GDPR (General Data Protection Regulation) and other regulations. This procedure, which involves making information completely unrecognizable, is the most straightforward and secure solution available in the industry. To summarize, data anonymization is an irreversible process that prevents an outsider from retrieving the original data value.
Conclusion
Data anonymization in today’s digital environment has become crucial for ensuring data privacy and meeting regulatory requirements such as GDPR, CCPA (California Consumer Privacy Act), and DPDPA. Cigniti assures clients that their applications adhere to compliance standards and maintain data privacy through robust protection measures for personally identifiable information (PII), protected health information (PHI), payment cardholder details (for PCI), and more by validating applications throughout the SDLC cycle, so that applications thoroughly tested at design level (Threat Modelling, Architecture Review), development level (Static Application Security Testing), deploy level (Dynamic Application Security Testing) and finally monitor level (Infrastructure Testing, SIEM, Sec Ops), with certified security testers with more than decades of experience.
Need help? Contact our Security Assurance experts to learn more about data anonymization techniques that can sustain data privacy and compliance standards.




Leave a Reply